- Count Sort
- PCB와 Constext Switching
- 트랜잭션 상태, 주의점
- JAVA - Collection API
이진 탐색 트리, TCP => 저번 study에 진행.
Count Sort
- 계수 정렬은 일반적인 상황이 아닌, 배열의 구성 요소들이 적은 범위로 자주 등장할 때 쓸 수 있는 정렬 기법으로
O(n)의 시간 복잡도를 지닌다. - 아이디어는, 여러번 반복되는 요소들을 한 번 쭉 훑으면서 등장하는 횟수를 센다.
- 그 횟수 배열을 작은 인덱스부터 누적합 배열로 갱신한다. 이 값이 새 위치 인덱스가 된다.
- 배열을 처음부터 훑으면서 등장하는 수의 누적합 값을 인덱스로 새 배열에 위치한다.
- 자기 자리를 찾았으면 자신에 해당하는 인덱스의 누적합을 -1 해준다.
- 즉 자기가 위치할 구간 정보가 누적합이고, 그 구간의 뒤에서부터 채우는 개념이다.
PCB & Context Switching
Process Management
CPU가 프로세스가 여러개일 때, CPU 스케줄링을 통해 관리하는 것을 말함
이때, CPU는 각 프로세스들이 누군지 알아야 관리가 가능함
프로세스들의 특징을 갖고있는 것이 바로 Process Metadata
- Process Metadata
- Process ID
- Process State
- Process Priority
- CPU Registers
- Owner
- CPU Usage
- Memeory Usage
이 메타데이터는 프로세스가 생성되면 PCB(Process Control Block)이라는 곳에 저장됨
PCB(Process Control Block)
프로세스 메타데이터들을 저장해 놓는 곳, 한 PCB 안에는 한 프로세스의 정보가 담김

다시 정리해보면?프로그램 실행 → 프로세스 생성 → 프로세스 주소 공간에 (코드, 데이터, 스택) 생성 → 이 프로세스의 메타데이터들이 PCB에 저장
PCB가 왜 필요한가요?
CPU에서는 프로세스의 상태에 따라 교체작업이 이루어진다. (interrupt가 발생해서 할당받은 프로세스가 wating 상태가 되고 다른 프로세스를 running으로 바꿔 올릴 때)
이때, 앞으로 다시 수행할 대기 중인 프로세스에 관한 저장 값을 PCB에 저장해두는 것이다.
PCB는 어떻게 관리되나요?
Linked List 방식으로 관리함
PCB List Head에 PCB들이 생성될 때마다 붙게 된다. 주소값으로 연결이 이루어져 있는 연결리스트이기 때문에 삽입 삭제가 용이함.
즉, 프로세스가 생성되면 해당 PCB가 생성되고 프로세스 완료시 제거됨
이렇게 수행 중인 프로세스를 변경할 때, CPU의 레지스터 정보가 변경되는 것을 Context Switching이라고 한다.
Context Switching
CPU가 이전의 프로세스 상태를 PCB에 보관하고, 또 다른 프로세스의 정보를 PCB에 읽어 레지스터에 적재하는 과정
보통 인터럽트가 발생하거나, 실행 중인 CPU 사용 허가시간을 모두 소모하거나, 입출랙을 위해 대기해야 하는 경우에 Context Switching이 발생
즉, 프로세스가 Ready → Running, Running → Ready, Running → Waiting처럼 상태 변경 시 발생!
Context Switching의 OverHead란?
overhead는 과부하라는 뜻으로 보통 안좋은 말로 많이 쓰인다.
하지만 프로세스 작업 중에는 OverHead를 감수해야 하는 상황이 있다.
프로세스를 수행하다가 입출력 이벤트가 발생해서 대기 상태로 전환시킴 이때, CPU를 그냥 놀게 놔두는 것보다 다른 프로세스를 수행시키는 것이 효율적
즉, CPU에 계속 프로세스를 수행시키도록 하기 위해서 다른 프로세스를 실행시키고 Context Switching 하는 것
CPU가 놀지 않도록 만들고, 사용자에게 빠르게 일처리를 제공해주기 위한 것이다.
트랜잭션의 상태
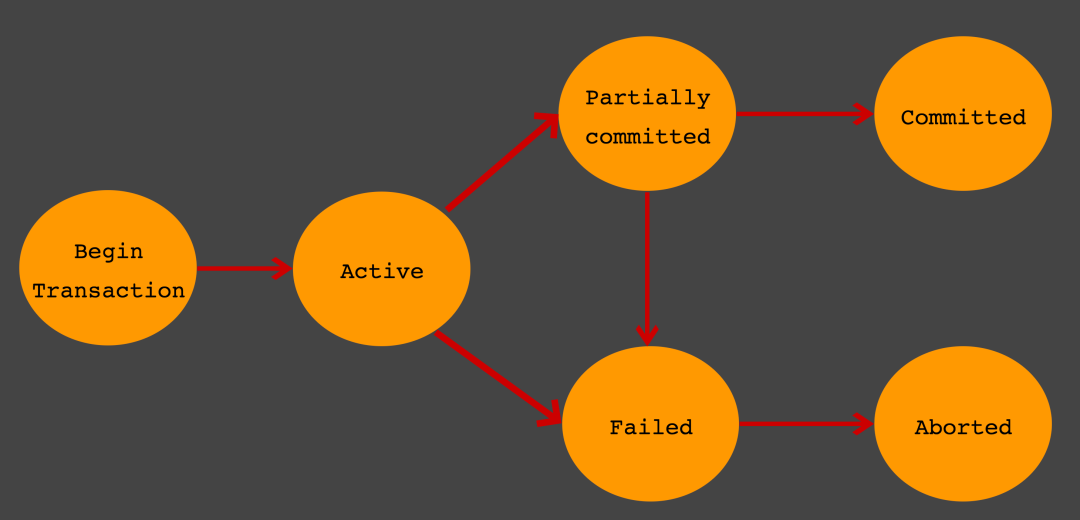
Active
트랜잭션의 활동 상태. 트랜잭션이 실행중이며 동작중인 상태를 말한다.
Failed
트랜잭션 실패 상태. 트랜잭션이 더이상 정상적으로 진행 할 수 없는 상태를 말한다.
Partially Committed
트랜잭션의 Commit 명령이 도착한 상태. 트랜잭션의 commit이전 sql문이 수행되고 commit만 남은 상태를 말한다.
Committed
트랜잭션 완료 상태. 트랜잭션이 정상적으로 완료된 상태를 말한다.
Aborted
트랜잭션이 취소 상태. 트랜잭션이 취소되고 트랜잭션 실행 이전 데이터로 돌아간 상태를 말한다.
Partially Committed 와 Committed 의 차이점
Commit 요청이 들어오면 상태는 Partial Commited 상태가 된다. 이후 Commit을 문제없이 수행할 수 있으면 Committed 상태로 전이되고, 만약 오류가 발생하면 Failed 상태가 된다. 즉, Partial Commited는 Commit 요청이 들어왔을때를 말하며, Commited는 Commit을 정상적으로 완료한 상태를 말한다.
트랜잭션을 사용할 때 주의할 점
트랜잭션은 꼭 필요한 최소의 코드에만 적용하는 것이 좋다. 즉 트랜잭션의 범위를 최소화하라는 의미다. 일반적으로 데이터베이스 커넥션은 개수가 제한적이다. 그런데 각 단위 프로그램이 커넥션을 소유하는 시간이 길어진다면 사용 가능한 여유 커넥션의 개수는 줄어들게 된다. 그러다 어느 순간에는 각 단위 프로그램에서 커넥션을 가져가기 위해 기다려야 하는 상황이 발생할 수도 있는 것이다.
Collection
Java Collection 에는 List, Map, Set 인터페이스를 기준으로 여러 구현체가 존재한다. 이에 더해 Stack과 Queue 인터페이스도 존재한다. 왜 이러한 Collection 을 사용하는 것일까? 그 이유는 다수의 Data 를 다루는데 표준화된 클래스들을 제공해주기 때문에 DataStructure 를 직접 구현하지 않고 편하게 사용할 수 있기 때문이다. 또한 배열과 다르게 객체를 보관하기 위한 공간을 미리 정하지 않아도 되므로, 상황에 따라 객체의 수를 동적으로 정할 수 있다. 이는 프로그램의 공간적인 효율성 또한 높여준다.
- List
List 인터페이스를 직접 @Override를 통해 사용자가 정의하여 사용할 수도 있으며, 대표적인 구현체로는 ArrayList가 존재한다. 이는 기존에 있었던 Vector를 개선한 것이다. 이외에도 LinkedList 등의 구현체가 있다. - Map
대표적인 구현체로 HashMap이 존재한다. (밑에서 살펴볼 멀티스레드 환경에서의 개발 부분에서 HashTable 과의 차이점에 대해 살펴본다.) key-value 의 구조로 이루어져 있으며 Map 에 대한 구체적인 내용은 DataStructure 부분의 hashtable 과 일치한다. key 를 기준으로 중복된 값을 저장하지 않으며 순서를 보장하지 않는다. key 에 대해서 순서를 보장하기 위해서는 LinkedHashMap을 사용한다. - Set
대표적인 구현체로 HashSet이 존재한다. value에 대해서 중복된 값을 저장하지 않는다. 사실 Set 자료구조는 Map 의 key-value 구조에서 key 대신에 value 가 들어가 value 를 key 로 하는 자료구조일 뿐이다. 마찬가지로 순서를 보장하지 않으며 순서를 보장해주기 위해서는 LinkedHashSet을 사용한다. - Stack 과 Queue
Stack 객체는 직접 new 키워드로 사용할 수 있으며, Queue 인터페이스는 JDK 1.5 부터 LinkedList에 new 키워드를 적용하여 사용할 수 있다. 자세한 부분은 DataStructure 부분의 설명을 참고하면 된다.
