- Trie 자료구조
- 이분 탐색 알고리즘
- 3-way handshake & 4-way handshake
- IPC (inter procsess communication)
- statement vs prepared statement
- JAVA 컴파일 과정
Trie(트라이)
Trie 자료구조란?
-
일반 트리 자료구조 중 하나로, Digital Tree, Radix Tree, Prefix Tree라고도 불린다.
-
텍스트 자동 완성 기능과 같이 문자열을 저장하고 탐색하는데 유용한 자료구조이다.
Trie 자료구조의 형태는?
-
각 노드는 <Key, Value> 맵을 가지고 있다. Key는 하나의 알파벳이 되고, Value는 그 Key에 해당하는 자식 노드가 된다.
-
다음은 DEV, DEAR, PIE, POP, POW라는 단어가 들어있는 Trie 자료구조를 도식화한 것이다. 휴대폰 전화번호부에서 검색을 하거나 사전에서 단어를 찾는 것과 같다.
-
예를 들어, 아래 그림에서 'DEV'라는 문자열을 찾으려면 루트 노드에서부터 순차적으로 [D] -> [E] -> [V] 를 탐색한다.
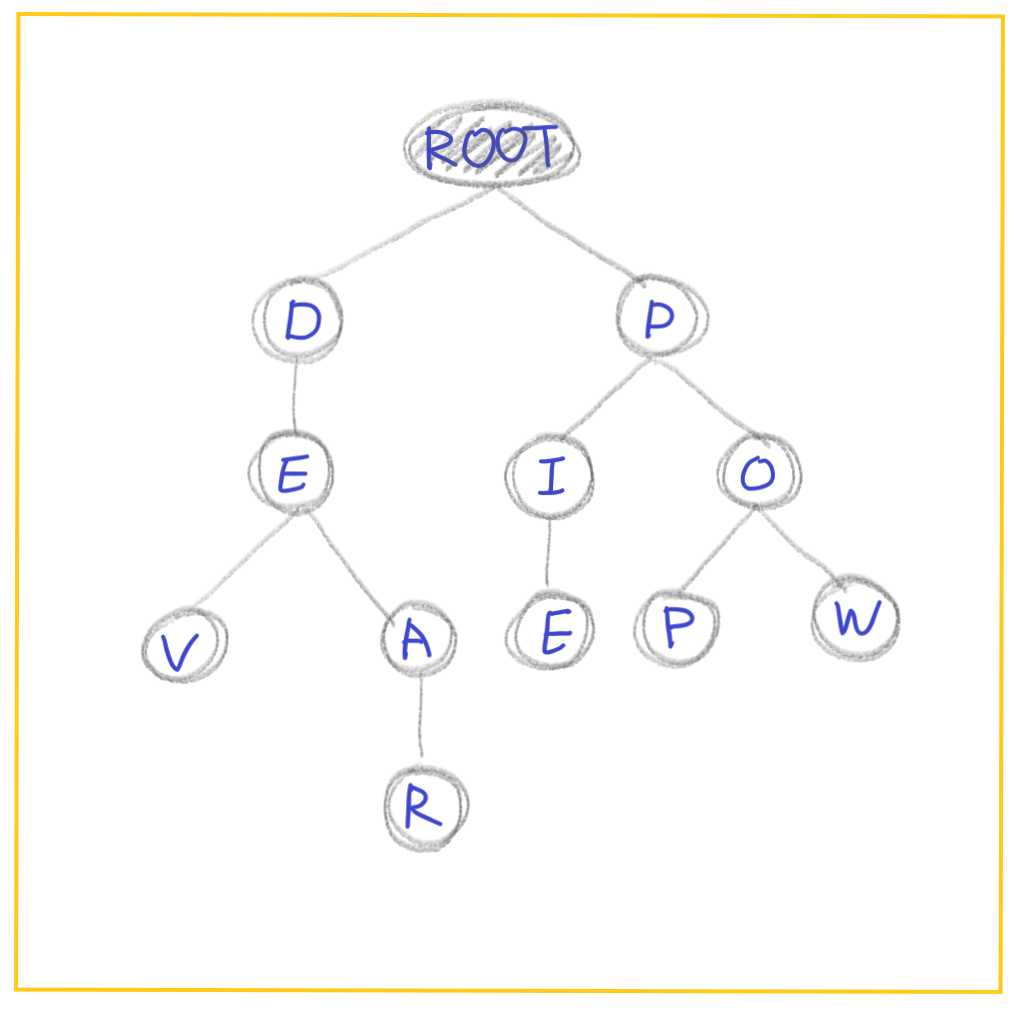
-
그림에서 볼 수 있듯이 루트 노드는 특정 문자를 의미하지 않고, 자식 노드만 가지고 있다.
-
유의할 점은 '부모 노드'나 '자신이 어떤 알파벳(Key)에 해당하는 노드(Value)'인지를 가지고 있는게 아니라는 점입니다.
-
즉, 루트 노드는 [D], [P]라고 하는 알파벳을 Key로 하는 자식 노드들을 가지고 있고, [D]는 [E]를 Key로 하는 자식 노드, [P]는 [I]와 [O]를 Key로 하는 자식 노드들을 가지고 있는 것이다.
-
또 루트 노드를 제외한 노드의 자손들은 해당 노드와 공통 접두어를 가진다는 특징이 있다. 즉, 'DE' 노드의 자손인 'DEAR'와 'DEV'는 'DE-'를 공통 접두어로 가지며, 'P'의 자손인 'POW'와 'PIE'는 'P-'를 공통 접두어로 가진다.

Trie 자료구조의 특징
-
정렬된 트리 구조이다.(데이터에 따라 이진트리일 때도 있다.)
-
Trie는 자식 노드를 Map<Key, Value> 형태로 가지고 있다.
-
루트 노드를 제외한 노드의 자손들은 해당 노드와 공통 접두어를 가진다.
-
루트 노드는 빈 문자와 연관있다.(특정 문자가 할당되어 있지 않다.)
이분 탐색(Binary Search)
- 이진 탐색 혹은 이분 탐색이라고 부른다.
- 이미 정렬되어 있는 자료 구조에서 특정 값을 찾을 때, 탐색 범위를 절반씩 나눠가면서 해당 값을 찾아가는 것이다.
- 즉, 탐색 범위를 두 부분으로 분할하면서 찾는 방식이다.
- 처음부터 끝까지 돌면서 탐색하는 것보다 훨씬 빠르다는 장점을 가지고 있다.
시간 복잡도
- 전체 탐색 : O(N)
- 이분 탐색 : O(logN)
진행 순서
- 정렬을 한다.
- left와 right로 mid 값을 설정한다.
- mid와 구하고자 하는 값을 비교한다.
- 구할 값이 mid보다 크면 -> left = mid + 1
- 구할 값이 mid보다 낮으면 -> right = mid - 1
- right < left가 될 때까지 계속 반복한다.
[TCP] 3 way handshake & 4 way handshake
연결을 성립하고 해제하는 과정을 말한다
3 way handshake - 연결 성립
TCP는 정확한 전송을 보장해야 한다. 따라서 통신하기에 앞서, 논리적인 접속을 성립하기 위해 3 way handshake 과정을 진행한다.

-
클라이언트가 서버에게 SYN 패킷을 보냄 (sequence : x)
-
서버가 SYN(x)을 받고, 클라이언트로 받았다는 신호인 ACK와 SYN 패킷을 보냄 (sequence : y, ACK : x + 1)
-
클라이언트는 서버의 응답은 ACK(x+1)와 SYN(y) 패킷을 받고, ACK(y+1)를 서버로 보냄
이렇게 3번의 통신이 완료되면 연결이 성립된다. (3번이라 3 way handshake인 것)
4 way handshake - 연결 해제
연결 성립 후, 모든 통신이 끝났다면 해제해야 한다.

-
클라이언트는 서버에게 연결을 종료한다는 FIN 플래그를 보낸다.
-
서버는 FIN을 받고, 확인했다는 ACK를 클라이언트에게 보낸다. (이때 모든 데이터를 보내기 위해 TIME OUT 상태가 된다)
-
데이터를 모두 보냈다면, 연결이 종료되었다는 FIN 플래그를 클라이언트에게 보낸다.
-
클라이언트는 FIN을 받고, 확인했다는 ACK를 서버에게 보낸다. (아직 서버로부터 받지 못한 데이터가 있을 수 있으므로 TIME_WAIT을 통해 기다린다.)
-
서버는 ACK를 받은 이후 소켓을 닫는다 (Closed)
-
TIME_WAIT 시간이 끝나면 클라이언트도 닫는다 (Closed)
이렇게 4번의 통신이 완료되면 연결이 해제된다.
IPC(Inter Process Communication)

프로세스는 독립적으로 실행된다. 즉, 독립 되어있다는 것은 다른 프로세스에게 영향을 받지 않는다고 말할 수 있다. (스레드는 프로세스 안에서 자원을 공유하므로 영향을 받는다)
이런 독립적 구조를 가진 프로세스 간의 통신을 해야 하는 상황이 있을 것이다. 이를 가능하도록 해주는 것이 바로 IPC 통신이다.
프로세스는 커널이 제공하는 IPC 설비를 이용해 프로세스간 통신을 할 수 있게 된다.
커널이란?
운영체제의 핵심적인 부분으로, 다른 모든 부분에 여러 기본적인 서비스를 제공해줌
IPC 설비 종류도 여러가지가 있다. 필요에 따라 IPC 설비를 선택해서 사용해야 한다.
IPC 종류
- 익명 PIPE
파이프는 두 개의 프로세스를 연결하는데 하나의 프로세스는 데이터를 쓰기만 하고, 다른 하나는 데이터를 읽기만 할 수 있다.
한쪽 방향으로만 통신이 가능한 반이중 통신이라고도 부른다.
따라서 양쪽으로 모두 송/수신을 하고 싶으면 2개의 파이프를 만들어야 한다.
매우 간단하게 사용할 수 있는 장점이 있고, 단순한 데이터 흐름을 가질 땐 파이프를 사용하는 것이 효율적이다. 단점으로는 전이중 통신을 위해 2개를 만들어야 할 때는 구현이 복잡해지게 된다.
- Named PIPE(FIFO)
익명 파이프는 통신할 프로세스를 명확히 알 수 있는 경우에 사용한다. (부모-자식 프로세스 간 통신처럼)
Named 파이프는 전혀 모르는 상태의 프로세스들 사이 통신에 사용한다.
즉, 익명 파이프의 확장된 상태로 부모 프로세스와 무관한 다른 프로세스도 통신이 가능한 것 (통신을 위해 이름있는 파일을 사용)
하지만, Named 파이프 역시 읽기/쓰기 동시에 불가능함. 따라서 전이중 통신을 위해서는 익명 파이프처럼 2개를 만들어야 가능
- Message Queue
입출력 방식은 Named 파이프와 동일함
다른점은 메시지 큐는 파이프처럼 데이터의 흐름이 아니라 메모리 공간이다.
사용할 데이터에 번호를 붙이면서 여러 프로세스가 동시에 데이터를 쉽게 다룰 수 있다.
- 공유 메모리
파이프, 메시지 큐가 통신을 이용한 설비라면, 공유 메모리는 데이터 자체를 공유하도록 지원하는 설비다.
프로세스의 메모리 영역은 독립적으로 가지며 다른 프로세스가 접근하지 못하도록 반드시 보호되야한다. 하지만 다른 프로세스가 데이터를 사용하도록 해야하는 상황도 필요할 것이다. 파이프를 이용해 통신을 통해 데이터 전달도 가능하지만, 스레드처럼 메모리를 공유하도록 해준다면 더욱 편할 것이다.
공유 메모리는 프로세스간 메모리 영역을 공유해서 사용할 수 있도록 허용해준다.
프로세스가 공유 메모리 할당을 커널에 요청하면, 커널은 해당 프로세스에 메모리 공간을 할당해주고 이후 모든 프로세스는 해당 메모리 영역에 접근할 수 있게 된다.
- 중개자 없이 곧바로 메모리에 접근할 수 있어서 IPC 중에 가장 빠르게 작동함
- 메모리 맵
공유 메모리처럼 메모리를 공유해준다. 메모리 맵은 열린 파일을 메모리에 맵핑시켜서 공유하는 방식이다. (즉 공유 매개체가 파일+메모리)
주로 파일로 대용량 데이터를 공유해야 할 때 사용한다.
- 소켓
네트워크 소켓 통신을 통해 데이터를 공유한다.
클라이언트와 서버가 소켓을 통해서 통신하는 구조로, 원격에서 프로세스 간 데이터를 공유할 때 사용한다.
서버(bind, listen, accept), 클라이언트(connect)
이러한 IPC 통신에서 프로세스 간 데이터를 동기화하고 보호하기 위해 세마포어와 뮤텍스를 사용한다. (공유된 자원에 한번에 하나의 프로세스만 접근시킬 때)
Statement vs PreparedStatement
우선 속도 면에서 PreparedStatement가 빠르다고 알려져 있다. 이유는 쿼리를 수행하기 전에 이미 쿼리가 컴파일 되어 있으며, 반복 수행의 경우 프리 컴파일된 쿼리를 통해 수행이 이루어지기 때문이다.
PreparedStatement에는 보통 변수를 설정하고 바인딩하는 static sql이 사용되고 Statement에서는 쿼리 자체에 조건이 들어가는 dynamic sql이 사용된다. PreparedStatement가 파싱 타임을 줄여주는 것은 분명하지만 static sql을 사용하는데 따르는 퍼포먼스 저하를 고려하지 않을 수 없다.
하지만 성능을 고려할 때 시간 부분에서 가장 큰 비중을 차지하는 것은 테이블에서 레코드(row)를 가져오는 과정이고 SQL 문을 파싱하는 시간은 이 시간의 10 분의 1 에 불과하다. 그렇기 때문에 SQL Injection 등의 문제를 보완해주는 PreparedStatement를 사용하는 것이 옳다.
자바 컴파일과정
들어가기전
자바는 OS에 독립적인 특징을 가지고 있습니다. 그게 가능한 이유는 JVM(Java Vitual Machine) 덕분인데요. 그렇다면 JVM(Java Vitual Machine)의 어떠한 기능 때문에, OS에 독립적으로 실행시킬 수 있는지 자바 컴파일 과정을 통해 알아보도록 하겠습니다.


자바 컴파일 순서
- 개발자가 자바 소스코드(.java)를 작성합니다.
- 자바 컴파일러(Java Compiler)가 자바 소스파일을 컴파일합니다. 이때 나오는 파일은 자바 바이트 코드(.class)파일로 아직 컴퓨터가 읽을 수 없는 자바 가상 머신이 이해할 수 있는 코드입니다. 바이트 코드의 각 명령어는 1바이트 크기의 Opcode와 추가 피연산자로 이루어져 있습니다.
- 컴파일된 바이크 코드를 JVM의 클래스로더(Class Loader)에게 전달합니다.
- 클래스 로더는 동적로딩(Dynamic Loading)을 통해 필요한 클래스들을 로딩 및 링크하여 런타임 데이터 영역(Runtime Data area), 즉 JVM의 메모리에 올립니다.
- 클래스 로더 세부 동작
- 로드 : 클래스 파일을 가져와서 JVM의 메모리에 로드합니다.
- 검증 : 자바 언어 명세(Java Language Specification) 및 JVM 명세에 명시된 대로 구성되어 있는지 검사합니다.
- 준비 : 클래스가 필요로 하는 메모리를 할당합니다. (필드, 메서드, 인터페이스 등등)
- 분석 : 클래스의 상수 풀 내 모든 심볼릭 레퍼런스를 다이렉트 레퍼런스로 변경합니다.
- 초기화 : 클래스 변수들을 적절한 값으로 초기화합니다. (static 필드)
- 클래스 로더 세부 동작
- 실행엔진(Execution Engine)은 JVM 메모리에 올라온 바이크 코드들을 명령어 단위로 하나씩 가져와서 실행합니다. 이때, 실행 엔진은 두가지 방식으로 변경합니다.
- 인터프리터 : 바이트 코드 명령어를 하나씩 읽어서 해석하고 실행합니다. 하나하나의 실행은 빠르나, 전체적인 실행 속도가 느리다는 단점을 가집니다.
- JIT 컴파일러(Just-In-Time Compiler) : 인터프리터의 단점을 보완하기 위해 도입된 방식으로 바이트 코드 전체를 컴파일하여 바이너리 코드로 변경하고 이후에는 해당 메서드를 더이상 인터프리팅 하지 않고, 바이너리 코드로 직접 실행하는 방식입니다. 하나씩 인터프리팅하여 실행하는 것이 아니라 바이트 코드 전체가 컴파일된 바이너리 코드를 실행하는 것이기 때문에 전체적인 실행속도는 인터프리팅 방식보다 빠릅니다.
