Minimum Spanning Tree
그래프 G 의 spanning tree 중 edge weight 의 합이 최소인 spanning tree를 말한다. 여기서 말하는 spanning tree란 그래프 G 의 모든 vertex 가 cycle 이 없이 연결된 형태를 말한다.
Kruskal Algorithm
초기화 작업으로 edge 없이 vertex 들만으로 그래프를 구성한다. 그리고 weight 가 제일 작은 edge 부터 검토한다. 그러기 위해선 Edge Set 을 non-decreasing 으로 sorting 해야 한다. 그리고 가장 작은 weight 에 해당하는 edge 를 추가하는데 추가할 때 그래프에 cycle 이 생기지 않는 경우에만 추가한다. spanning tree 가 완성되면 모든 vertex 들이 연결된 상태로 종료가 되고 완성될 수 없는 그래프에 대해서는 모든 edge 에 대해 판단이 이루어지면 종료된다.
Kruskal Algorithm의 세부 동작과정 Kruskal Algorithm 관련 Code
어떻게 cycle 생성 여부를 판단하는가?
Graph 의 각 vertex 에 set-id라는 것을 추가적으로 부여한다. 그리고 초기화 과정에서 모두 1~n 까지의 값으로 각각의 vertex 들을 초기화 한다. 여기서 0 은 어떠한 edge 와도 연결되지 않았음을 의미하게 된다. 그리고 연결할 때마다 set-id를 하나로 통일시키는데, 값이 동일한 set-id 개수가 많은 set-id 값으로 통일시킨다.
Time Complexity
- Edge 의 weight 를 기준으로 sorting - O(E log E)
- cycle 생성 여부를 검사하고 set-id 를 통일 - O(E + V log V) => 전체 시간 복잡도 : O(E log E)
Prim Algorithm
초기화 과정에서 한 개의 vertex 로 이루어진 초기 그래프 A 를 구성한다. 그리고나서 그래프 A 내부에 있는 vertex 로부터 외부에 있는 vertex 사이의 edge 를 연결하는데 그 중 가장 작은 weight 의 edge 를 통해 연결되는 vertex 를 추가한다. 어떤 vertex 건 간에 상관없이 edge 의 weight 를 기준으로 연결하는 것이다. 이렇게 연결된 vertex 는 그래프 A 에 포함된다. 위 과정을 반복하고 모든 vertex 들이 연결되면 종료한다.
Time Complexity
=> 전체 시간 복잡도 : O(E log V)
LCA(Lowest Common Ancestor) 알고리즘
최소 공통 조상 찾는 알고리즘
→ 두 정점이 만나는 최초 부모 정점을 찾는 것!
트리 형식이 아래와 같이 주어졌다고 하자
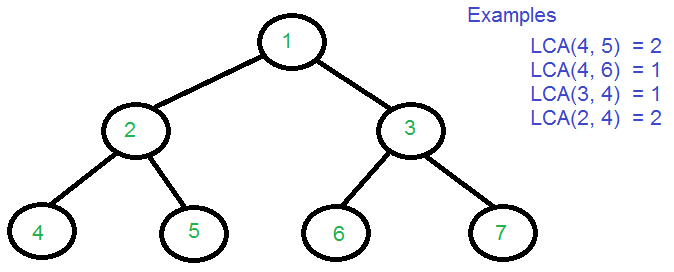
4와 5의 LCA는? → 4와 5의 첫 부모 정점은 '2'
4와 6의 LCA는? → 첫 부모 정점은 root인 '1'
어떻게 찾죠?
해당 정점의 depth와 parent를 저장해두는 방식이다. 현재 그림에서의 depth는 아래와 같을 것이다.
[depth : 정점] 0 → 1(root 정점)
1 → 2, 3
2 → 4, 5, 6, 7
parent는 정점마다 가지는 부모 정점을 저장해둔다. 위의 예시에서 저장된 parent 배열은 아래와 같다.
// 1 ~ 7번 정점 (root는 부모가 없기 때문에 0)
int parent[] = {0, 1, 1, 2, 2, 3, 3}
이제
이 두 배열을 활용해서 두 정점이 주어졌을 때 LCA를 찾을 수 있다. 과정은 아래와 같다.
// 두 정점의 depth 확인하기
while(true){
if(depth가 일치)
if(두 정점의 parent 일치?) LCA 찾음(종료)
else 두 정점을 자신의 parent 정점 값으로 변경
else // depth 불일치
더 depth가 깊은 정점을 해당 정점의 parent 정점으로 변경(depth가 감소됨)
}
트리 문제에서 공통 조상을 찾아야하는 문제나, 정점과 정점 사이의 이동거리 또는 방문경로를 저장해야 할 경우 사용하면 된다.
주소창에 naver.com을 치면 일어나는 일
면접 질문에서도 종종 나오는 방식이다. 이해하기 전에 IP 주소와 도메인에 대한 사전 지식이 필요하다.
IP 주소
- IP 주소란 많은 컴퓨터들이 인터넷 상에서 서로를 인식하기 위해 지정받은 식별용 번호라고 생각하면 된다.
- 현재는 IPv4 버전(32비트)로 구성되어 있으며, 한번씩은 들어봤을 법한 127.0.0.1 같은 주소를 말한다.
- 시간이 갈수록 IPv4 주소의 부족으로 IPv6가 생겼는데, 128비트로 구성되어 있기 때문에 IP 주소가 부족하지 않다는 특징이 있다.
도메인 네임(Domain Name)
- IP 주소는 12자리의 숫자로 되어 있기 때문에 사람이 외우기 힘들다는 단점이 있다.
- 그렇기 때문에 12자리의 IP 주소를 문자로 표현한 주소를 도메인 네임이라고 한다.
- 다시 말해서, 도메인 네임은 'naver.com'처럼 몇 개의 의미있는 문자들과 .의 조합으로 구성된다.
- 도메인 네임은 사람의 편의성을 위해 만든 주소이므로 실제로는 컴퓨터가 이해할 수 있는 IP 주소로 변환하는 작업이 필요하다.
- 이때, 사용할 수 있도록 미리 도메인 네임과 함께 해당하는 IP 주소값을 한 쌍으로 저장하고 있는 데이터베이스를 DNS(Domain Name System) 이라고 부른다.
- 도메인 네임으로 입력하면 DNS를 이용해 컴퓨터는 IP 주소를 받아 찾아갈 수 있다.
작동 방식

- 사용자가 브라우저에 도메인 네임(www.naver.com)을 입력한다.
- 사용자가 입력한 URL 주소 중에서 도메인 네임(Domain Name) 부분을 DNS 서버에서 검색하고, DNS 서버에서 해당 도메인 네임에 해당하는 IP 주소를 찾아 사용자가 입력한 URL 정보와 함께 전달한다.
- 페이지 URL 정보와 전달받은 IP 주소는 HTTP 프로토콜을 사용하여 HTTP 요청 메시지를 생성하고, 이렇게 생성된 HTTP 요청 메시지는 TCP 프로토콜을 사용하여 인터넷을 거쳐 해당 IP 주소의 컴퓨터로 전송된다.
- 이렇게 도착한 HTTP 요청 메시지는 HTTP 프로토콜을 사용하여 웹 페이지 URL 정보로 변환되어 웹 페이지 URL 정보에 해당하는 데이터를 검색한다.
- 검색된 웹 페이지 데이터는 또 다시 HTTP 프로토콜을 사용하여 HTTP 응답 메시지를 생성하고 TCP 프로토콜을 사용하여 인터넷을 거쳐 원래 컴퓨터로 전송된다.
- 도착한 HTTP 응답 메시지는 HTTP 프로토콜을 사용하여 웹 페이지 데이터로 변환되어 웹 브라우저에 의해 출력되어 사용자가 볼 수 있게 된다.
이렇게 말하면 어느 정도 설명할 수 있지만, 뭔가 부족하다. 조금 더 알아보자.
DHCP & ARP
대부분의 가정집에서는 DHCP로 인터넷 접속을 하고 있다. DHCP는 Dynamic Host Configuration Protocol의 약자로, 호스트의 IP 주소 및 TCP / IP 설정을 클라이언트에 자동으로 제공하는 프로토콜이다. 사용자의 PC는 DHCP 서버에서 사용자 자신의 IP 주소, 가장 가까운 라우터의 IP 주소, 가장 가까운 DNS 서버의 IP 주소를 받는다. 이후, ARP 프로토콜을 이용하여 IP 주소를 기반으로 가장 가까운 라우터의 MAC 주소를 알아낸다.

DHCP 서버의 동작 개념도 - 클라이언트가 인터넷 접속을 시도하면 IP와 기본 정보를 제공해준다.
IP 정보 수신
위의 과정을 통해 외부와 통신할 준비를 마쳤으므로, DNS Query를 DNS 서버에 전송한다. DNS 서버는 이에 대한 결과로 웹 서버의 IP 주소를 사용자 PC에 돌려준다. DNS 서버가 도메인에 대한 IP 주소를 송신하는 과정은 약간 복잡하다.
과정 (www.naver.com 이라고 가정하자.)
사용자의 PC는 가장 먼저 지정된 DNS 서버(우리나라의 경우, 통신사별로 지정된 DNS 서버가 있다.)에 DNS Query를 송신한다. 그 후 지정된 DNS 서버는 Root 네임서버에 www.naver.com을 질의하고, Root 네임서버는 .com 네임서버의 ip 주소를 알려준다.
그 후 .com 네임서버에 www.naver.com을 질의하면 naver.com 네임서버의 ip 주소를 받고 그곳에 질의를 또 송신하면 www.naver.com의 IP 주소를 수신하게 된다.
이와 같이 여러번 왔다갔다 하는 이유는, 도메인의 계층화 구조에 따라 DNS 서버도 계층화 되어있기 때문이다. 이렇게 계층화되어 있으므로 도메인의 가장 최상단, 즉 가장 뒷쪽(.com, .kr 등등)을 담당하는 DNS 서버는 전세계에 13개 뿐이다.
웹 서버 접속
이제 웹 서버의 IP 주소까지 알았다. Http Request를 위헤 TCP Socket을 개방하고 연결한다. 이 과정에서 3-way hand shaking 과정이 일어난다. TCP 연결에 성공하면, Http Request가 TCP Socket을 통해 보내진다. 이에 대한 응답으로 웹 페이지의 정보가 사용자의 PC로 들어온다.
참고
- [Network] 주소창에 www.naver.com을 치면 일어나는 일
- IT 기술면접 준비자료 당신이 브라우저로 웹사이트에 접속할 때 일어나는 일들 (부제: DNS 이야기)
- 브라우저로 웹 사이트에 접속할 때 과정
[커널모드의 동기화]
- 세마포어(Semaphore)
- 공유된 자원의 데이터를 여러 프로세스, 스레드가 접근하는 것을 막는 것이다.
- 동시에 접근할 수 있는 '허용 가능한 갯수'를 가지고 있는 Counter. (공유자원에 접근할 수 있는 스레드 혹은 프로세스의 수를 나타내는 값. -> 공통으로 관리하는 하나의 값)
- Ex)
- 화장실을 예로 들어보자. 세마포어는 1개 이상의 열쇠라고 할 수 있다. 화장실 칸이 4개이고 열쇠가 4개라면, 4명까지는 대기없이 바로 사용할 수 있다. 그 다음부터는 대기를 해야 한다. 이것이 바로 세마포어이다.
- 세마포어 Counter의 갯수에 따라 다음과 같이 나뉜다.
- 1개 : Binary Semaphore(뮤텍스와 같다.)
- 2개 이상 : Counting Semaphore
- 세마포어는 소유할 수 없다.
- 세마포어를 소유하지 않은 스레드가 세마포어를 해제할 수 있는 문제가 발생한다.
- 뮤텍스(Mutal Exclusion)
- 공유된 자원의 데이터를 여러 프로세스, 스레드가 접근하는 것을 막는 것이다.
- 임계 구역을 가진 스레드들의 Running time이 서로 겹치지 않게 각각 단독으로 실행되게 하는 기술이다.
- 뮤텍스 객체를 두 스레드가 동시에 사용할 수 없다.
- 일종의 Locking 매커니즘으로 공유 자원에 대한 접근을 조율하기 위해 locking과 unlocking을 사용한다.
- Lock에 대한 소유권이 있으며 Lock을 가지고 있을 경우에만 공유 자원에 접근할 수 있고, Lock을 가진 사람만 반납할 수 있다.
- 뮤텍스는 무조건 1개의 열쇠만 가질 수 있다. 열쇠를 가진 사람만이 화장실에 갈 수 있고, 다음 사람이 화장실에 가기 위해서는 앞 사람이 열쇠를 반납해야 한다.
- 모니터(Monitor)
- Mutex(Lock)와 Condition Variables를 가지고 있는 Synchronization 매커니즘이다.
뮤텍스와 모니터는 상호 배제를 함으로써 임계 구역에 하나의 쓰레드만 들어갈 수 있다.
반면, 세마포어는 하나의 쓰레드만 들어가거나 혹은 여러개의 쓰레드가 들어가게 할 수도 있다.
Q. 임계영역이란?
- 둘 이상의 스레드가 동시에 접근해서는 안되는 공유 자원을 접근하는 코드의 일부를 말한다.
- 임계 영역에서 동기화를 진행하지 못하면 치명적인 문제가 발생.
- 따라서 임계 구역 문제를 해결하기 위해서는 3가지 필수 조건이 있다.
- 상호 배제(Mutual exclusion) : 프로세스 P1이 공유 자원을 접근하는 임계 구역 코드를 수행하고 있으면 다른 프로세스들은 공유 자원을 접근하는 임계 구역 코드를 수행할 수 없다. 즉, 한 순간에 하나의 스레드만이 실행될 수 있다.
- 진행(Progress) : 임계 구역에서 실행중인 프로세스가 없고 별도의 동작이 없는 프로세스들만 임계 구역 진입 후보로서 참여될 수 있다.
- 한정된 대기(Bounded Waiting) : P1이 임계 구역에 진입 신청 후부터 받아들여질때까지, 다른 프로세스들이 임계 구역에 진입하는 횟수는 제한이 있어야 한다.
Q. 뮤텍스와 모니터의 차이는?
- 뮤텍스는 다른 프로세스나 스레드 간에 동기화를 위해 사용한다.
- 모니터는 하나의 프로세스내에서 다른 스레드 간에 동기화할 때 사용한다.
- 뮤텍스는 운영체제 커널에 의해 제공된다.
- 무겁고 느리다.
- 모니터는 프레임워크나 라이브러리 그 자체에서 제공된다.
- 가볍고 빠르다.
Q. 세마포어와 모니터의 차이는?
- 자바에서는 모니터를 모든 객체에게 기본적으로 제공하지만 C에서는 사용할 수 없음.
- 세마포어는 카운터라는 변수값으로 프로그래머가 상호 배제나 정렬의 목적으로 사용시 매번 값을 따로 지정해줘야 하는 등 조금 번거롭다.
- 반면, 모니터는 이러한 일들이 캡슐화되어 있어서 개발자는 카운터 값을 0 또는 1으로 주어야 하는 고민을 할 필요가 없이 synchronized, wait(), notify() 등의 키워드를 이용해 좀 더 편하게 동기화할 수 있다.
Q. 세마포어와 뮤텍스의 차이는?
- 세마포어는 뮤텍스가 될 수 있지만, 뮤텍스는 세마포어가 될 수 없다.
- 세마포어는 소유할 수 없으며, 뮤텍스는 소유할 수 있고 소유주가 그 책임을 진다.
- 뮤텍스의 경우 뮤텍스를 소유하고 있는 스레드가 이 뮤텍스를 해제할 수 있다. 하지만 세마포어는 소유하지 않고 있는 다른 스레드가 세마포어를 해제할 수 있다.
- 뮤텍스는 동기화 대상이 1개일 때 사용하고 세마포어는 동기화 대상이 여러 개일때 사용한다.
DataBase - Key 종류
- Key란? 검색이나 정렬 시 Tuple을 구분할 수 있는 기준이 되는 Attribute.
1. Candidate Key(후보키)
- 릴레이션을 구성하는 속성들 중에서 Tuple을 유일하게 식별할 수 있는 속성들의 부분 집합을 의미한다.(기본키로 사용할 수 있는 속성들을 후보키라 한다.)
- 모든 릴레이션은 반드시 하나 이상의 후보 키를 가져야 한다.
- 릴레이션에 있는 모든 튜플에 대해서 유일성과 최소성을 만족시켜야 한다.
아래 2가지 조건을 만족해야 한다.
- 유일성 : Key로 하나의 Tuple을 유일하게 식별할 수 있음.
- 최소성 : 꼭 필요한 속성으로만 구성.
Ex)
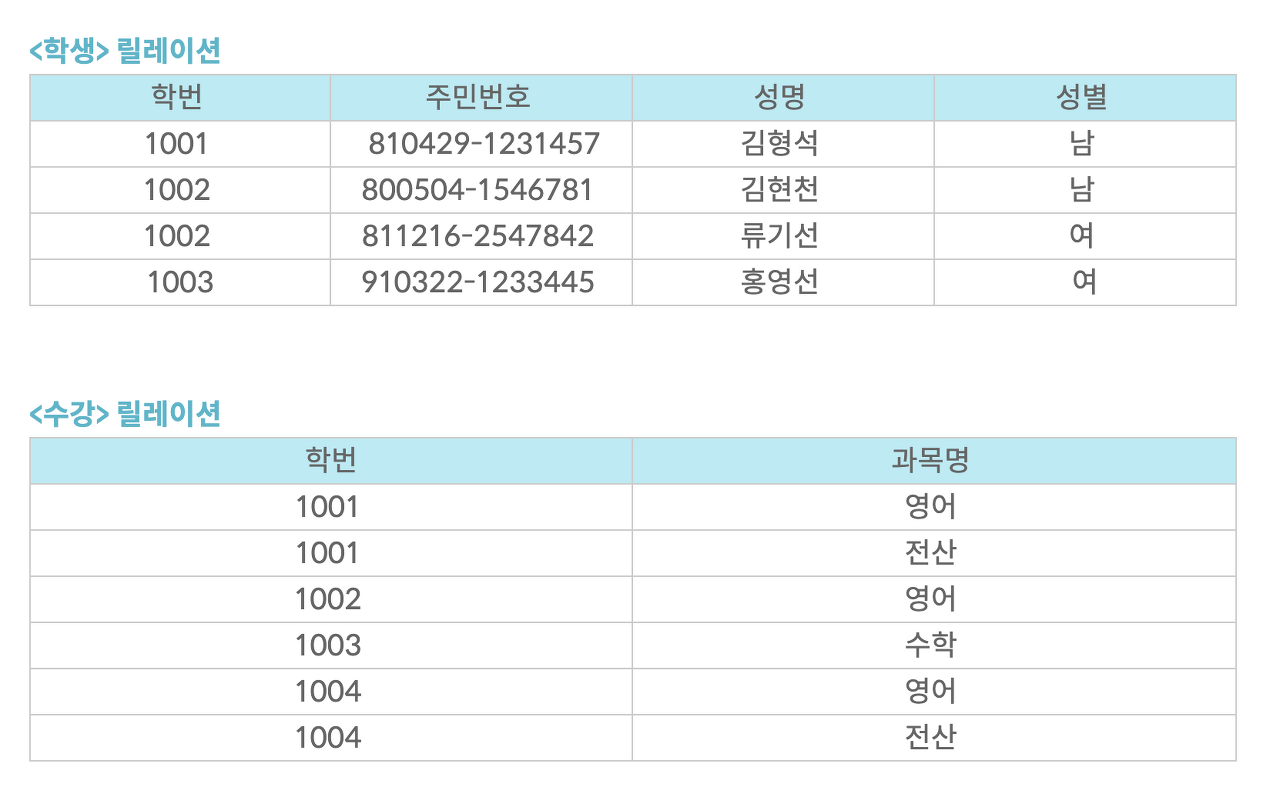
[학생] 릴레이션에서 학번이나 주민번호는 다른 레코드를 유일하게 구별할 수 있는 기본키로 사용할 수 있으므로 후보키가 될 수 있다. 즉, 기본키가 될 수 있는 키들을 후보키라 한다.
2. Primary Key(기본키)
- 후보 키 중 선택한 Main key
- 한 릴레이션에서 특정 튜플을 유일하게 구별할 수 있는 속성
- Null 값을 가질 수 없다.(개체 무결성의 첫 번째 조건)
- 기본 키로 정의된 속성에는 동일한 값이 중복되어 저장될 수 없다.(개체 무결성의 두 번째 조건)
아래 조건을 만족해야 한다.
- 유일성 : 기본키를 구성하는 컬럼은 테이블에서 레코드를 식별할 수 있도록 유일해야 한다.
- 최소성 : 유일성을 만족하는 한도 내에서 최소한의 컬럼(하나 이상)으로 구성되어야 한다.
- 개체 무결성 : 기본키가 가지고 있는 값의 유일성을 보장받아야 한다.
Ex)
[학생] 릴레이션에는 학번이나 주민 번호가 기본키가 될 수 있고, [수강] 릴레이션에는 학번+과목명으로 조합해야 기본키가 만들어질 수 있다. 왜냐하면 [수강] 릴레이션에서는 학번 속성과 과목명 속성은 개별적으로 기본키로 사용할 수 없다. 다른 튜플들과 구별되지 않기 때문이다.
3. Alternate Key(대체키)
- 후보키가 둘 이상일 때, 기본 키를 제외한 나머지 후보키들을 말한다.
- 보조키라고도 한다.
Ex)
[학생] 릴레이션에서 학번을 기본키로 정하면 주민번호 는 대체키가 된다.
4. Super Key(슈퍼키)
- 한 릴레이션 내에 있는 속성들의 집합으로 구성된 키로서 릴레이션을 구성하는 모든 튜플 중 슈퍼키로 구성된 속성의 집합과 동일한 값을 나타내지 않는다.
- 릴레이션을 구성하는 모든 튜플에 대해서 유일성은 만족하지만, 최소성은 만족시키지 못한다.
Ex)
[학생] 릴레이션에서는 학번, 주민번호, 학번+주민번호, 학번+주민번호+성명 등으로 슈퍼키를 구성할 수 있다. 또한, 여기서 최소성을 만족시키지 못한다는 말은 학번+주민번호+성명이 슈퍼키인 경우, 3개의 속성 조합을 통해 다른 튜플과 구별이 가능하지만, 성명 단독적으로 슈퍼키를 사용했을 때는 구별이 가능하지 않기 때문에 최소성을 만족시키지 못한다.
즉, 뭉쳤을 경우 유일성이 생기고 흩어지면 몇몇 속성들은 독단적으로 유일성이 있는 키로 사용할 수 없다. 이것을 최소성을 만족하지 못한다고 한다.
5. Foreignn Key(외래키)
- 관계(Relation)를 맺고 있는 릴레이션 R1,R2에서 릴레이션 R1이 참조하고 있는 릴레이션 R2의 기본키와 같은 R1 릴레이션의 속성을 외래키라고 한다.
- 외래키는 참조되는 릴레이션의 기본키와 대응되어 릴레이션 간에 참조 관계를 표현하는 데 중요한 도구로 사용된다.
- 외래키로 지정되면 참조 테이블의 기본키에 없는 값은 입력할 수 없다.(참조 무결성의 조건)
Ex)
[수강] 릴레이션이 [학생] 릴레이션을 참조하고 있으므로, [학생] 릴레이션의 학번은 기본키이고, [수강] 릴레이션의 학번은 외래키이다.
즉, 각 릴레이션의 입장에서 속성은 기본키가 되기도 하고, 외래키가 되기도 한다.
-> [수강] 릴레이션의 학번에는 [학생] 릴레이션의 학번에 없는 값은 입력할 수 없다.
기타
Null 값?
데이터베이스에서 아직 알려지지 않았거나, 모르는 값으로서 "해당 없음" 등의 이유로 정보 부재를 나타내기 위해 사용하는, 이론적으로 아무것도 없는 특수한 데이터를 뜻한다.
참고
JAVA - Generic
제네릭은 자바에서 안정성을 맡고 있다고 할 수 있다. 다양한 타입의 객체들을 다루는 메서드나 컬렉션 클래스에서 사용하는 것으로, 컴파일 과정에서 타입체크를 해주는 기능이다. 객체의 타입을 컴파일 시에 체크하기 때문에 객체의 타입 안전성을 높이고 형변환의 번거로움을 줄여준다. 자연스럽게 코드도 더 간결해진다. 예를 들면, Collection 에 특정 객체만 추가될 수 있도록, 또는 특정한 클래스의 특징을 갖고 있는 경우에만 추가될 수 있도록 하는 것이 제네릭이다. 이로 인한 장점은 collection 내부에서 들어온 값이 내가 원하는 값인지 별도의 로직처리를 구현할 필요가 없어진다. 또한 api 를 설계하는데 있어서 보다 명확한 의사전달이 가능해진다.
JAVA - 전역, 지역, 클래스 변수를 자바의 메모리 구조와 관련해서 생각해보기

- 메소드 영역
- 클래스에 대한 정보와 함께 클래스 변수(static variable)가 저장되는 영역.
- JVM은 자바 프로그램에서 특정 클래스가 사용되면 해당 클래스의 클래스 파일(*.class)을 읽어들여, 클래스에 대한 정보를 메소드 영역에 저장한다.
- 힙 영역
- 모든 인스턴스 변수(멤버 변수)가 저장되는 영역.
- new 키워드를 사용해 인스턴스가 생성되면, 해당 인스턴스의 정보를 힙 영역에 저장한다.
- 힙 영역은 메모리의 낮은 주소 -> 높은 주소의 방향으로 할당된다.
- 스택 영역
- 메소드가 호출될 때, 메소드의 스택 프레임이 저장되는 영역.
- 메소드 호출 시, 메소드 호출과 관계되는 매개변수와 지역 변수를 스택 영역에 저장한다.
- 스택 영역은 메소드의 호출과 함께 할당되며, 메소드의 호출이 완료되면 소멸한다.
- 스택 영역에 저장되는 메소드의 호출 정보를 스택 프레임이라고 부른다.
- 후입 선출의 구조를 갖고 있으며, 메모리의 높은 주소에서 낮은 주소의 방향으로 할당된다.
[선언 위치에 따른 변수의 종류]
- 클래스, 지역, 인스턴스 변수가 있으며 선언된 위치에 따라 종류가 결정된다.
public class Test{
int iv; // 인스턴스 변수.
static int cv; // 클래스 변수.
void print(){
int lv; // 지역 변수.
}
}- iv, cv는 클래스 내부에 선언되어 있으므로 멤버 변수.
- cv는 static으로 선언되었으니 클래스 변수이고, iv는 인스턴스 변수.
- lv는 메소드 내에 선언되었으므로 지역 변수.
- 인스턴스 변수
- 인스턴스가 생성될 때, 생성된다. 따라서 인스턴스 변수를 사용하기 전에 먼저 객체를 생성해야 한다.
- 인스턴스 변수는 독립적인 저장공간을 가지므로 인스턴스 별로 다른 값을 가질 수 있다.
- 따라서 각 인스턴스마다 고유의 값을 가져야 할 때는 인스턴스 변수로 선언한다.
- 힙 영역에 올라간다.
- 클래스 변수
- static 키워드가 붙은 변수이다.
- 클래스 변수는 해당 클래스의 모든 인스턴스가 공통된 값을 공유하게 된다.
- 따라서 한 클래스의 모든 인스턴스가 공통적인 값을 가져야할 때, 클래스 변수로 선언한다.
- 클래스가 로딩될 때, 생성되어(그러므로 메모리에 딱 한번만 올라간다.) 종료될 때까지 유지되는 클래스 변수는 public을 붙이면 같은 프로그램 내에서 어디서든 접근 가능한 전역 변수가 된다.
- 인스턴스 생성 없이 접근할 수 있으므로 클래스이름.클래스변수 를 통해 접근할 수 있다.
- 메소드 영역에 올라가며, 주로 공유의 목적으로 사용한다.
- 지역 변수
- 메소드 내에 선언되며 메소드 내에서만 사용할 수 있는 변수이다.
- 메소드가 실행될 때, 메모리를 할당받으며 메소드가 끝나면 소멸되어 사용할 수 없게 된다.
- 스택 영역에 올라간다.
