유니온 파인드(Union Find)란?
정의
- 유니온 파인드(Union Find): 서로소 집합(Disjoint Set) 그리고 병합 찾기 집합(Merge Find Set)이라고도 불리며 여러 서로소 집합의 정보를 저장하고 있는 자료구조를 의미합니다.
예시
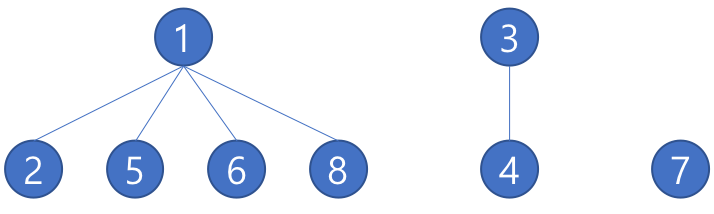
- 다음 아래와 같이 원소들이 있다고 가정을 했을 때

- 각각의 원소들이 어떤 원소들과 연결이 되어있는지 입력을 받는다고 가정하면(1-2, 2-5, 5-6, 5-8, 3-4 이런 방식으로) 아래와 같이 3개의 서로소 집합이 나올 수 있다.

구현
원리
- 배열을 이용해서 Tree 자료구조를 만들어 구현하며 위에 나와 있는 {1, 2, 5, 6, 8}, {3, 4}, {7}의 경우에는 아래처럼 표현 및 구현이 가능합니다.
- 즉, 최상단 노드인 Root노드를 집합을 구분하는 ID처럼 생각하면 이해가 더 편합니다.
- 주어진 두 원소 또는 집합을 합하는 Union부분과 원소가 어떤 집합에 있는지 찾는 Find함수로 이루어져있다.
- parent[i]: 원소 i의 부모 노드를 가지고 있는 배열, parent[i]는 i의 부모 노드
초기화
- 처음에 각각의 원소들은 연결된 정보가 없기 때문에 부모로 자기 자신을 가지고 있다.
- 즉, parent[i] = i;
for(int i=1; i<=n; i++){
parent[i] = i;
}
Find 함수
- Find(x) 함수: x로 들어온 원소의 Root노드를 반환
int Find(int x){
// Root인 경우 x를 반환
if(x == parent[x]){
return x;
}
else{
// 아니면 Root를 찾아감
int p = Find(parent[x]);
parent[x] = p;
return p;
}
}
Union 함수
- Union(x,y) 함수: x원소와 y원소를 합치는 함수로 y의 Root노드를 x로 한다.
// x와 y의 원소가 들어오면
// 각각 x에는 들어온 x의 Root 노드 y에는 들어온 y의 Root 노드를 저장해서 비교하고
// x에 y를 붙이는 방식 -> y의 Root 노드를 x로 설정
void Union(int x, int y){
x = Find(x);
y = Find(y);
if(x!=y){
parent[y] = x;
}
}
비트마스크(BitMask)
집합의 요소들의 구성 여부를 표현할 때 유용한 테크닉
왜 비트마스크를 사용하는가?
-
DP나 순열 등, 배열 활용만으로 해결할 수 없는 문제
-
작은 메모리와 빠른 수행시간으로 해결이 가능 (But, 원소의 수가 많지 않아야 함)
-
집합을 배열의 인덱스로 표현할 수 있음
-
코드가 간결해짐
비트(Bit)란?
컴퓨터에서 사용되는 데이터의 최소 단위 (0과 1)
2진법을 생각하면 편하다.
우리가 흔히 사용하는 10진수를 2진수로 바꾸면?
9(10진수) → 1001(2진수)
비트마스킹 활용해보기
0과 1로, flag 활용하기
[1, 2, 3, 4 ,5] 라는 집합이 있다고 가정해보자.
여기서 임의로 몇 개를 골라 뽑아서 확인을 해야하는 상황이 주어졌다. (즉, 부분집합을 의미)
{1}, {2} , ... , {1,2} , ... , {1,2,5} , ... , {1,2,3,4,5}
물론, 간단히 for문 돌려가며 배열에 저장하며 경우의 수를 구할 순 있다.
하지만 비트마스킹을 하면, 각 요소를 인덱스처럼 표현하여 효율적인 접근이 가능하다.
[1,2,3,4,5] → 11111 [2,3,4,5] → 11110 [1,2,5] → 10011 [2] → 00010
집합의 i번째 요소가 존재하면 1, 그렇지 않으면 0을 의미하는 것이다.
이러한 2진수는 다시 10진수로 변환도 가능하다.
11111은 10진수로 31이므로, 부분집합을 정수를 통해 나타내는 것이 가능하다는 것을 알 수 있다.
31은 [1,2,3,4,5] 전체에 해당하는 부분집합에 해당한다는 의미!
이로써, 해당 부분집합에 i를 추가하고 싶을때 i번째 비트를 1로만 바꿔주면 표현이 가능해졌다.
이런 행위는 비트 연산을 통해 제어가 가능하다.
비트 연산
AND, OR, XOR, NOT, SHIFT
-
AND(&) : 대응하는 두 비트가 모두 1일 때, 1 반환
-
OR(|) : 대응하는 두 비트 중 모두 1이거나 하나라도 1일때, 1 반환
-
XOR(^) : 대응하는 두 비트가 서로 다를 때, 1 반환
-
NOT(~) : 비트 값 반전하여 반환
-
SHIFT(>>, <<) : 왼쪽 혹은 오른쪽으로 비트 옮겨 반환
- 왼쪽 시프트 : A * 2^B
- 오른쪽 시프트 : A / 2^B
1.삽입
현재 이진수로 10101로 표현되고 있을 때, i번째 비트 값을 1로 변경하려고 한다.
i = 3일 때 변경 후에는 11101이 나와야 한다. 이때는 OR연산을 활용한다.
10101 | 1 << 3
1 << 3은 1000이므로 10101 | 01000이 되어 11101을 만들 수 있다.
2.삭제
반대로 0으로 변경하려면, AND연산과 NOT 연산을 활용한다.
11101 & ~1 << 3
~1 << 3은 10111이므로, 11101 & 10111이 되어 10101을 만들 수 있다.
3.조회
i번째 비트가 무슨 값인지 알려면, AND연산을 활용한다.
10101 & 1 << i 3번째 비트 값 : 10101 & (1 << 3) = 10101 & 01000 → 0 4번째 비트 값 : 10101 & (1 << 4) = 10101 & 10000 → 10000
이처럼 결과값이 0이 나왔을 때는 i번째 비트 값이 0인 것을 파악할 수 있다. (반대로 0이 아니면 무조건 1인 것)
이러한 방법을 활용하여 문제를 해결하는 것이 비트마스크다.
비트마스크 연습문제 : 백준 2098
해당 문제는 모든 도시를 한 번만 방문하면서 다시 시작점으로 돌아오는 최소 거리 비용을 구해야한다.
완전탐색으로 답을 구할 수는 있지만, N이 최대 16이기 때문에 16!으로 시간초과에 빠지게 된다.
따라서 DP를 활용해야 하며, 방문 여부를 배열로 관리하기 힘드므로 비트마스크를 활용하면 좋은 문제다.
1. Stateful Service
Stateful '구조'는 Server와 Client간 세션의 'State(상태)'에 기반하여 Client에 response를 보냅니다.
이를 위해 세션 '상태'를 포함한 Client와의 세션 정보를 server에 저장하게 됩니다.
대표적인 Stateful 구조를 따르는 프로토콜로 TCP가 있습니다.
TCP의 3-way handshaking 과정을 생각해봅시다.
Server와 Client는 3-way handshaking 과정에서 SYN과 SYNACK을 주고 받으며,
양단간 세션 '상태'를 established한 '상태'로 만듭니다.
세션 '상태'가 established가 되면 client와 server는 데이터를 주고 받을 수 있습니다.
이렇게 TCP는 세션 '상태'에 따라 Server의 응답이 달라지는 Stateful 프로토콜입니다.
TCP의 데이터 전송과정도 확인해 봅시다.
server는 client로부터 송신된 패킷헤더를 파싱하여
앞으로 수신해야할 데이터의 크기(window), sequence 번호 등을 저장합니다.
그리고 해당 크기의 데이터가 모두 수신 될 때까지 client와의 세션을 유지합니다.
이 과정에서 server는 앞으로 수신할 데이터의 크기, sequence 번호 등과 같이 client와의 세션 정보를 저장하게 됩니다.

TCP (출처 : https://brunch.co.kr/@lars/1)
따라서 TCP는 Client와의 세션 정보를 server에 저장하고,
세션 상태에 기반한 server의 응답이 달라진다는 점에서 Stateful 하다고 말할 수 있습니다.
Stateful Service는 이러한 Stateful한 특성,
1. 세션 정보를 server에 저장, 2. 세션 'State(상태)'에 따른 응답
를 만족하도록 설계된 서비스 구조 입니다.
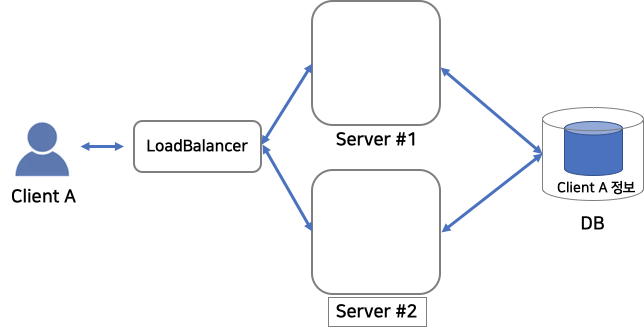
아래의 사진과 같은 Stateful Service 구조를 생각해 봅시다.
ClientA 의 요청이 로드밸런서를 통해 임의의 서버, 그림의 경우 Server#1, 에 전달되면
Server#1 에는 ClientA 의 세션 정보가 저장 됩니다.
그러나 로드밸런서에 연결된 다른 server, 그림의 경우 Server#2, 에는 해당 ClientA에 대한 정보가 없으므로
Server#2는 Client A와의 세션 인증을 처음부터 다시 해야할 필요가 있으며,
이러한 redundant한 작업을 없애기 위해 ClientA의 요청은 Server#1을 향해 유지되도록 관리가 필요합니다.

Stateful Service Architecture
2. Stateless Service
Stateless '구조'는 server의 응답이 client와의 세션 '상태'와 독립적입니다.
Stateless 구조에서 server는 단순히 요청이 오면 응답을 보내는 역할만 수행하며, 세션 관리는 client에게 책임이 있습니다.
따라서 이러한 Stateless 구조는 client와의 세션 정보를 기억할 필요가 없으므로, 이러한 정보를 서버에 저장하지 않습니다.
대신 필요에 따라 외부 DB에 저장하여 관리 할 수 있습니다.
대표적인 Stateless 프로토콜로는 UDP와 HTTP 등이 있습니다.
여기서는 UDP를 예로 들어 보겠습니다.
아시다시피, UDP는 TCP와 달리 handshaking 과정을 통해 연결 세션을 인증하는 절차를 수행하지 않습니다.
세션 상태에 관계 없이 단순히 데이터그램을 source에서 destination 쪽으로 전송합니다.
client가 송신하려 했던 모든 데이터가 server쪽에 수신 되었는지 확인하지 않습니다.
따라서 server쪽은 client와의 세션 정보를 전혀 저장하지 않습니다.

TCP vs. UDP (출처 : https://www.muvi.com/wiki/udpuser-datagram-protocol.html)
따라서 UDP는 Client와의 세션 상태에 관계없이 요청에 대한 응답만을 수행합니다.
또한 Client와의 세션 정보를 server가 저장하지 않는다는 점에서 Stateless 하다고 말할 수 있습니다.
Stateless Service는 이러한 Stateless한 특성,
1. 세션 정보를 server에 저장하지 않음, 2. 세션 'State(상태)'에 무관한 응답
를 만족하도록 설계된 서비스 구조 입니다.
아래와 같은 Stateless 서비스 구조를 생각해 봅시다.
이번에도 Client A의 요청이 로드밸런서를 통해 Server#1 으로 전달 되었다고 가정해 봅시다.
Stateful 서비스 구조에서는 server에 직접 ClientA와의 세션 정보를 저장했지만.
Stateless 서비스 구조에서는 이 정보를 server에 저장하지 않고, 외부 DB에 저장합니다.
따라서 ClientA의 요청이 Server#2로 전달 되더라도, Server#2는 DB를 통해 ClientA 정보에 접근 가능합니다.
이러한 Stateless 구조에서는 ClientA의 요청을 Server#1에만 유지되도록 관리할 필요가 없습니다.
Stateless Service Architecture
3. Why Stateless Service?
위에서도 눈치 채셨겠지만, Statelss 구조가 Stateful 구조 대비 갖는 몇가지 장점들로 인해
최근의 웹서비스 구조는 모두 Stateless 구조 기반을 따르고 있습니다.
그렇다면 Stateless Service가 어떤 점에서 유리할까요?
여러가지 이유가 있겠지만, 제가 생각하는 stateless 구조의 가장 큰 이점만 소개하겠습니다.
바로 Scaling이 자유롭다는 것입니다.
트래픽의 급증으로 서버가 scale out된 상황을 생각 해봅시다.
- Stateful 서비스의 경우,
client의 세션 정보가 새로 scale out된 서버에 저장 되어 있지 않습니다!
따라서 세션 정보를 옮겨주는 등의 부수적인 관리가 요구 됩니다.

Scaling Out of Stateful Service
-Stateless 서비스의 경우,
어차피 server는 client 세션 관리를 하지 않으므로, 걱정할 필요가 없습니다!
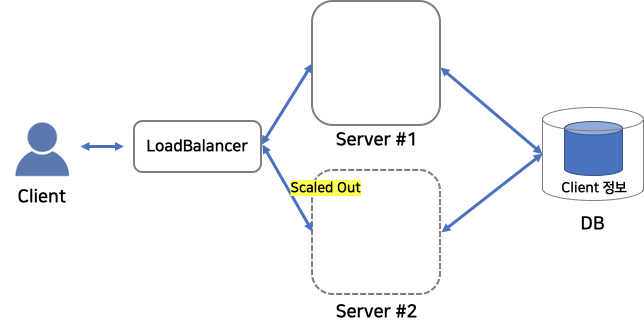
Scaling Out of Stateless Service
scaling은 최근 웹 서비스들이 요구하는 중요한 기능입니다.
serverless 구조의 서비스 구현에서는 필수적입니다.
따라서 최근 웹 서비스 트렌드 동향에 발맞춰, scaling이 자유로운 Stateless 서비스 구조가 각광받고 있습니다.
4. Stateless Service 및 HTTP, REST
stateless service를 검색하면 나오는 연관 검색어들이 HTTP, REST 입니다.
각 용어 들의 대분류를 해봅시다.
Stateless 와 Representational State Transfer (REST)는 '구조(Architecture)' 의 이름 입니다.
반면 HTTP는 프로토콜 입니다.
그럼 각 용어들의 정의 해봅시다.
2장에서 말했 듯, HTTP는 Stateless한 프로토콜 입니다.
그리고 REST는 이러한 HTTP 프로토콜 상에 구현된 Resource Oriented Architecture (ROA) 설계 구조 입니다.
따라서 HTTP와 REST 모두 Stateless한 성격을 가진 녀석들이며,
HTTP는 Statelss한 성격을 가진 '프로토콜'
REST는 Stateless한 성격을 가진 '설계 구조'
이다.. 정도로 이해해주시면 될 것 같습니다.
페이지 교체 알고리즘
페이지 부재 발생 → 새로운 페이지를 할당해야 함 → 현재 할당된 페이지 중 어떤 것 교체할 지 결정하는 방법
- 좀 더 자세하게 생각해보면?
가상 메모리는 요구 페이지 기법을 통해 필요한 페이지만 메모리에 적재하고 사용하지 않는 부분은 그대로 둠
하지만 필요한 페이지만 올려도 메모리는 결국 가득 차게 되고, 올라와있던 페이지가 사용이 다 된 후에도 자리만 차지하고 있을 수 있음
따라서 메모리가 가득 차면, 추가로 페이지를 가져오기 위해서 안쓰는 페이지는 out하고, 해당 공간에 현재 필요한 페이지를 in 시켜야 함
여기서 어떤 페이지를 out 시켜야할 지 정해야 함. (이때 out 되는 페이지를 victim page라고 부름)
기왕이면 수정이 되지 않는 페이지를 선택해야 좋음 (Why? : 만약 수정되면 메인 메모리에서 내보낼 때, 하드디스크에서 또 수정을 진행해야 하므로 시간이 오래 걸림)
이와 같은 상황에서 상황에 맞는 페이지 교체를 진행하기 위해 페이지 교체 알고리즘이 존재하는 것!
Page Reference String
CPU는 논리 주소를 통해 특정 주소를 요구함
메인 메모리에 올라와 있는 주소들은 페이지의 단위로 가져오기 때문에 페이지 번호가 연속되어 나타나게 되면 페이지 결함 발생 X
따라서 CPU의 주소 요구에 따라 페이지 결함이 일어나지 않는 부분은 생략하여 표시하는 방법이 바로 Page Reference String
- FIFO 알고리즘
First-in First-out, 메모리에 먼저 올라온 페이지를 먼저 내보내는 알고리즘
가장 간단한 방법으로, 특히 초기화 코드에서 적절한 방법임
초기화 코드 : 처음 프로세스 실행될 때 최초 초기화를 시키는 역할만 진행하고 다른 역할은 수행하지 않으므로, 메인 메모리에서 빼도 괜찮음
하지만 처음 프로세스 실행시에는 무조건 필요한 코드이므로, FIFO 알고리즘을 사용하면 초기화를 시켜준 후 가장 먼저 내보내는 것이 가능함
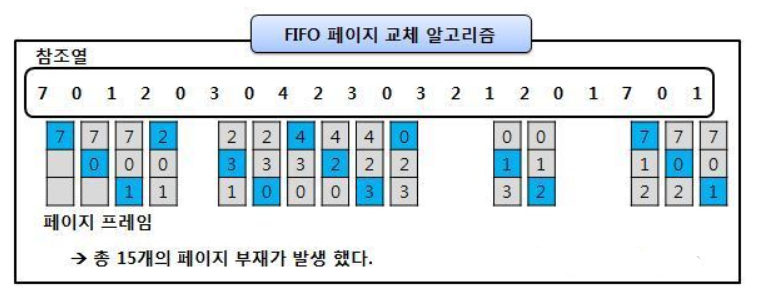
- victim page : out 되는 페이지는, 가장 먼저 메모리에 올라온 페이지
- OPT 알고리즘
Optimal Page Replacement 알고리즘, 앞으로 가장 사용하지 않을 페이지를 가장 우선적으로 내보냄
하지만, 실질적으로 페이지가 앞으로 잘 사용되지 않을 것이라는 보장이 없기 때문에 수행하기 어려운 알고리즘임
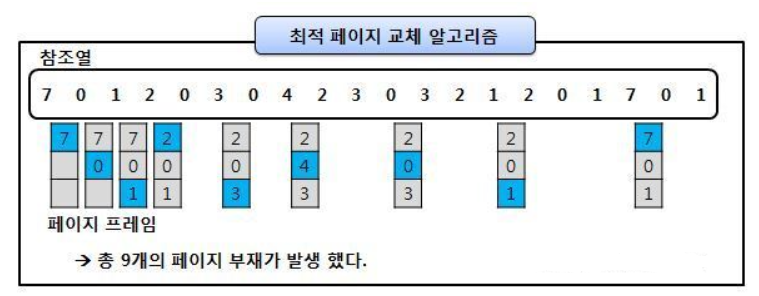
- FIFO에 비해 페이지 결함의 횟수를 많이 감소시킬 수 있음
- LRU 알고리즘
Least-Recently-Used, 최근에 사용하지 않은 페이지를 가장 먼저 내려보내는 알고리즘
OPT의 경우 미래 예측이지만, LRU의 경우는 과거를 보고 판단하므로 실질적으로 사용이 가능한 알고리즘
(실제로도 최근에 사용하지 않은 페이지는 앞으로도 사용하지 않을 확률이 높다)
OPT보다는 페이지 결함이 더 일어날 수 있지만, 실제로 사용할 수 있는 페이지 교체 알고리즘에서는 가장 좋은 방법 중 하나임
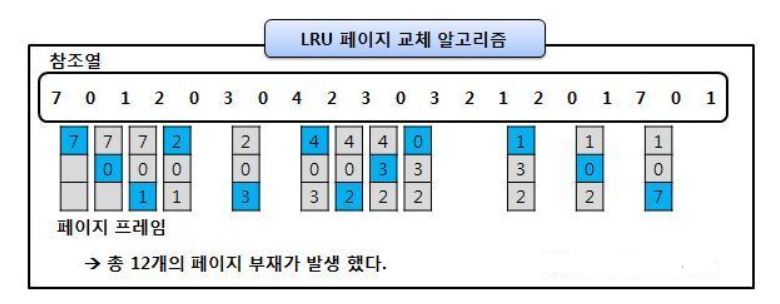
- 최근에 사용하지 않았으면, 나중에도 사용되지 않을 것이라는 아이디어에서 나옴
교체 방식
-
Global 교체
메모리 상의 모든 프로세스 페이지에 대해 교체하는 방식
-
Local 교체
메모리 상의 자기 프로세스 페이지에서만 교체하는 방식
다중 프로그래밍의 경우, 메인 메모리에 다양한 프로세스가 동시에 올라올 수 있음
따라서, 다양한 프로세스의 페이지가 메모리에 존재함
페이지 교체 시, 다양한 페이지 교체 알고리즘을 활용해 victim page를 선정하는데, 선정 기준을 Global로 하느냐, Local로 하느냐에 대한 차이
→ 실제로는 전체를 기준으로 페이지를 교체하는 것이 더 효율적이라고 함. 자기 프로세스 페이지에서만 교체를 하면, 교체를 해야할 때 각각 모두 교체를 진행해야 하므로 비효율적
SQL Injection
해커에 의해 조작된 SQL 쿼리문이 데이터베이스에 그대로 전달되어 비정상적 명령을 실행시키는 공격 기법
공격 방법1) 인증 우회
보통 로그인을 할 때, 아이디와 비밀번호를 input 창에 입력하게 된다. 쉽게 이해하기 위해 가벼운 예를 들어보자. 아이디가 abc, 비밀번호가 만약 1234일 때 쿼리는 아래와 같은 방식으로 전송될 것이다.
SELECT * FROM USER WHERE ID = "abc" AND PASSWORD = "1234";
SQL Injection으로 공격할 때, input 창에 비밀번호를 입력함과 동시에 다른 쿼리문을 함께 입력하는 것이다.
1234; DELETE * USER FROM ID = "1";
보안이 완벽하지 않은 경우, 이처럼 비밀번호가 아이디와 일치해서 True가 되고 뒤에 작성한 DELETE 문도 데이터베이스에 영향을 줄 수도 있게 되는 치명적인 상황이다.
이 밖에도 기본 쿼리문의 WHERE 절에 OR문을 추가하여 '1' = '1'과 같은 true문을 작성하여 무조건 적용되도록 수정한 뒤 DB를 마음대로 조작할 수도 있다.
2) 데이터 노출
시스템에서 발생하는 에러 메시지를 이용해 공격하는 방법이다. 보통 에러는 개발자가 버그를 수정하는 면에서 도움을 받을 수 있는 존재다. 해커들은 이를 역이용해 악의적인 구문을 삽입하여 에러를 유발시킨다.
즉 예를 들면, 해커는 GET 방식으로 동작하는 URL 쿼리 스트링을 추가하여 에러를 발생시킨다. 이에 해당하는 오류가 발생하면, 이를 통해 해당 웹앱의 데이터베이스 구조를 유추할 수 있고 해킹에 활용한다.
방어 방법1) input 값을 받을 때, 특수문자 여부 검사하기
로그인 전, 검증 로직을 추가하여 미리 설정한 특수문자들이 들어왔을 때 요청을 막아낸다.
2) SQL 서버 오류 발생 시, 해당하는 에러 메시지 감추기
view를 활용하여 원본 데이터베이스 테이블에는 접근 권한을 높인다. 일반 사용자는 view로만 접근하여 에러를 볼 수 없도록 만든다.
3) preparestatement 사용하기
preparestatement를 사용하면, 특수문자를 자동으로 escaping 해준다. (statement와는 다르게 쿼리문에서 전달인자 값을 ?로 받는 것) 이를 활용해 서버 측에서 필터링 과정을 통해서 공격을 방어한다.
Multi-Thread 환경에서의 개발
개발을 시작하는 입장에서 멀티 스레드를 고려한 프로그램을 작성할 일이 별로 없고 실제로 부딪히기 힘든 문제이기 때문에 많은 입문자들이 잘 모르고 있는 부분 중 하나라고 생각한다. 하지만 이 부분은 정말 중요하며 고려하지 않았을 경우 엄청난 버그를 양산할 수 있기 때문에 정말 중요하다.
Field member
필드(field)란 클래스에 변수를 정의하는 공간을 의미한다. 이곳에 변수를 만들어두면 메소드 끼리 변수를 주고 받는 데 있어서 참조하기 쉬우므로 정말 편리한 공간 중 하나이다. 하지만 객체가 여러 스레드가 접근하는 싱글톤 객체라면 field 에서 상태값을 갖고 있으면 안된다. 모든 변수를 parameter 로 넘겨받고 return 하는 방식으로 코드를 구성해야 한다.
동기화(Synchronized)
필드에 Collection 이 불가피하게 필요할 때는 어떠한 방법을 사용할까? Java 에서는 synchronized 키워드를 사용하여 스레드 간 race condition 을 통제한다. 이 키워드를 기반으로 구현된 Collection 들도 많이 존재한다. List를 대신하여 Vector를 사용할 수 있고, Map을 대신하여 HashTable을 사용할 수 있다. 하지만 이 Collection 들은 제공하는 API 가 적고 성능도 좋지 않다.
기본적으로는 Collections라는 util 클래스에서 제공되는 static 메소드를 통해 이를 해결할 수 있다. Collections.synchronizedList(), Collections.synchronizedSet(), Collections.synchronizedMap() 등이 존재한다. JDK 1.7 부터는 concurrent package를 통해 ConcurrentHashMap이라는 구현체를 제공한다. Collections util 을 사용하는 것보다 synchronized 키워드가 적용된 범위가 좁아서 보다 좋은 성능을 낼 수 있는 자료구조이다.
ThreadLocal
스레드 사이에 간섭이 없어야 하는 데이터에 사용한다. 멀티스레드 환경에서는 클래스의 필드에 멤버를 추가할 수 없고 매개변수로 넘겨받아야 하기 때문이다. 즉, 스레드 내부의 싱글톤을 사용하기 위해 사용한다. 주로 사용자 인증, 세션 정보, 트랜잭션 컨텍스트에 사용한다.
스레드 풀 환경에서 ThreadLocal 을 사용하는 경우 ThreadLocal 변수에 보관된 데이터의 사용이 끝나면 반드시 해당 데이터를 삭제해 주어야 한다. 그렇지 않을 경우 재사용되는 쓰레드가 올바르지 않은 데이터를 참조할 수 있다.
ThreadLocal 을 사용하는 방법은 간단하다.
- ThreadLocal 객체를 생성한다.
- ThreadLocal.set() 메서드를 이용해서 현재 스레드의 로컬 변수에 값을 저장한다.
- ThreadLocal.get() 메서드를 이용해서 현재 스레드의 로컬 변수 값을 읽어온다.
- ThreadLocal.remove() 메서드를 이용해서 현재 스레드의 로컬 변수 값을 삭제한다.
